

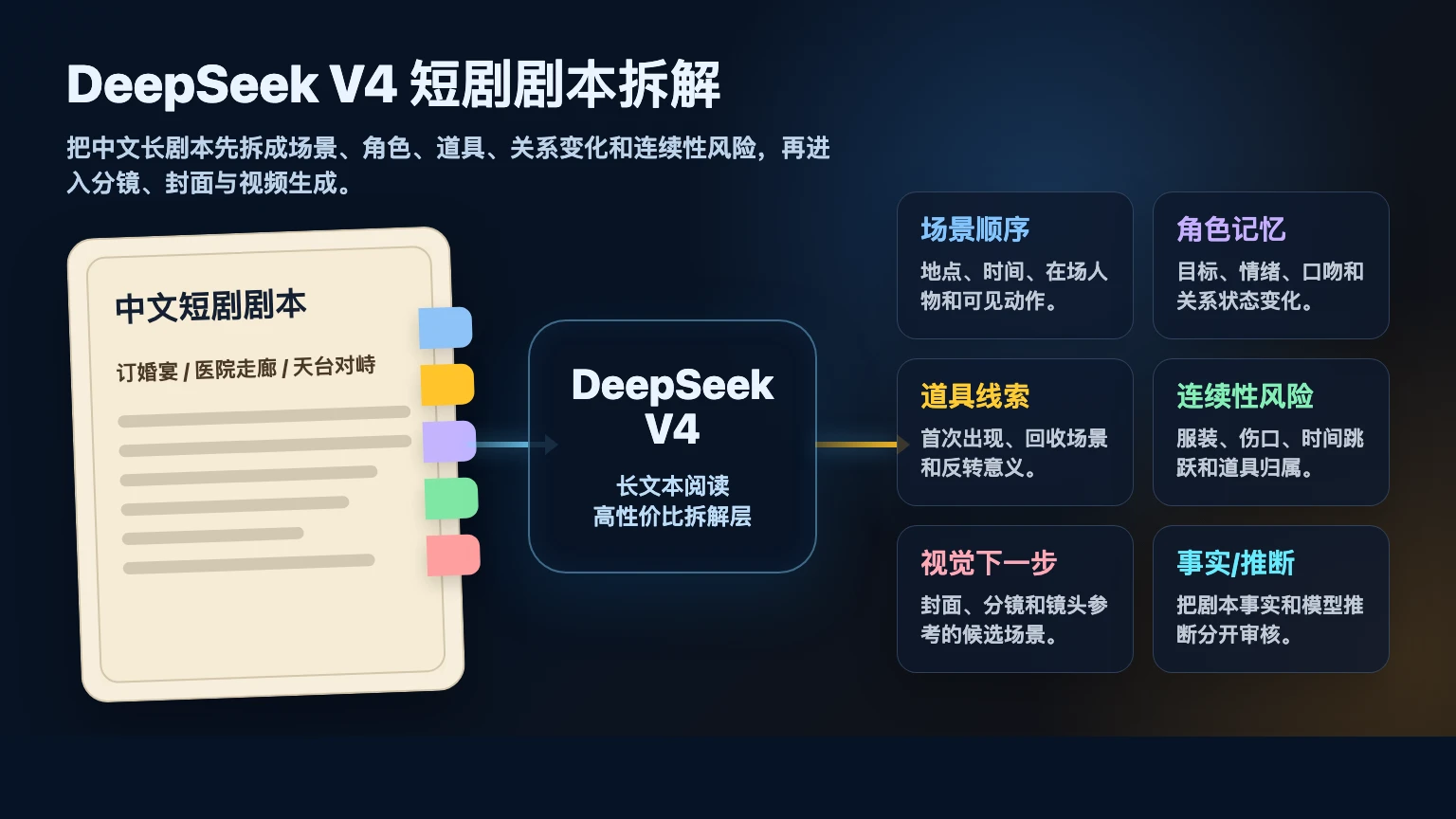
DeepSeek V4 适合放在中文 AI 短剧制作的第一层:先读剧本,再把故事拆成后续生产能用的结构。它不应该只输出剧情总结。更有价值的结果,是把长剧本拆成场景表、角色记忆、道具线索、关系变化、情绪转折、连续性风险和下一步画面建议。
对 Arcloop 这样的剧本优先视频智能体来说,问题不是“DeepSeek V4 能不能概括一集短剧”,而是“它能不能把剧本变成角色设定、分镜、封面、宣传图和视频镜头都能复用的故事记忆”。DeepSeek 的优势在于中文理解、长文本处理和成本效率;Arcloop 要做的不是宣传某一次模型调用,而是把剧本读解、角色连续性、视觉规划和视频生成前的审核串成一个制作系统。
先把剧本拆成制作笔记
DeepSeek V4 做 AI 短剧剧本拆解时,最好把它当成长文本阅读和结构化生产笔记层。输入应该是剧本、分场、人物表或分集大纲;输出应该包括场景顺序、出场人物、关键道具、关系变化、情绪转折、连续性约束和视觉下一步。不要只要一句剧情简介,也不要让它直接决定最终封面或视频镜头。
如果你做的是中文短剧,真正麻烦的往往不是“这集讲什么”,而是订婚宴、医院走廊、天台对峙、替身身份、戒指线索这些细节怎么一路传到分镜、封面和视频镜头里。DeepSeek V4 更适合先把这些信息拆成制作笔记,再交给 Arcloop 的视频智能体继续组织后面的画面素材。Arcloop 的 agent 文本模型能力对创作者免费开放,适合反复跑剧本拆解、重写结构和校对连续性,而不是每次都担心文本分析成本。
如果你已经厌倦了反复修改“容易违规、容易跑偏”的提示词,也可以把 DeepSeek V4 加持下的 Arcloop agent 当成提示词整理层。它的作用不是帮你绕过审核,而是把含混、夸张、容易触发审核的描述,改写成角色、场景、镜头、动作边界和可见细节都更清楚的制作说明。这样后面的图片和视频生成更容易稳定,也更容易被人工审核。
版本提示:先确认你实际调用的 DeepSeek 模型
DeepSeek V4 是当前适合拿来讨论长文本剧本拆解的模型名称。DeepSeek 官方 V4 Preview 发布页强调了更长上下文、推理和文本生成能力,模型与价格页也列出了 V4 Flash、V4 Pro 等模型选项。对短剧团队来说,重点不是“换一个模型名”,而是用性能更强、价格更有竞争力的文本模型,把剧本拆解变成可以高频执行的前置工序。
但模型服务会持续更新。生产环境里不要承诺“固定使用某个外部模型版本”。更稳的写法是:这篇文章按 DeepSeek V4 的长文本剧本拆解能力来讲方法,实际调用以前以 DeepSeek 官方模型页、价格页和 Arcloop 当前产品配置为准。
DeepSeek V4 适合解决什么短剧问题
短剧剧本不是一段普通长文本。它有角色反复出现、道具前后回收、关系不断变化、情绪节点密集、每集都有剧情看点,还要继续进入分镜、封面、宣传图和视频生成。
DeepSeek V4 这类长文本模型适合先处理这些“读剧本”的问题:
| 剧本问题 | 拆解输出 | 后续用途 |
|---|---|---|
| 一集里发生了哪些场景 | 场景表、地点、时间、可见动作 | 分镜和镜头规划 |
| 哪些角色在场、谁说话、谁只是被提到 | 出场人物表、说话人物、缺席人物 | 角色连续性手册和对白检查 |
| 哪个物品会成为线索或反转 | 道具线索、首次出现、回收场景 | 封面、宣传图和连续性审核 |
| 哪段关系发生变化 | 信任、背叛、权力、亲密度变化 | 封面看点和镜头距离 |
| 哪个情绪是本集转折 | 情绪节拍、冲突升级、悬念点 | 3x3 分镜图和预告图 |
| 哪些信息不能在生成时丢失 | 服装、伤口、时间、道具归属 | 图片和视频连续性 |
这才是“剧本拆解”的生产价值。总结剧情只是第一步,不能直接支撑后面的画面制作。
不要让 DeepSeek V4 只写剧情梗概
弱的输出通常是这样的:
- “这一集讲述了女主被背叛后复仇。”
- “男主和女主之间的误会进一步加深。”
- “剧情节奏紧张,适合做悬疑风格短剧。”
这些句子不一定错,但无法进入生产。强的剧本拆解应该给出可执行信息:
- “第 3 场发生在医院走廊,女主第一次发现病例编号和母亲旧案有关。”
- “戒指在第 1 场作为婚约物出现,第 7 场变成男主识破替身身份的证据。”
- “女主在第 5 场之前一直穿白色外套,第 6 场被泼红酒后服装状态必须延续到天台对峙。”
- “第 8 场不是普通争吵,而是信任关系断裂,适合做封面或 3x3 分镜里的反转格。”
DeepSeek V4 的输出越接近制作笔记,后续视频智能体越容易使用。
一个适合短剧的 DeepSeek V4 拆解提示词
可以先从这个提示词开始测试,重点不是让模型“写得更长”,而是让它把剧本信息拆到后续制作能直接使用的粒度。
你是短剧制作里的剧本拆解助理。
请不要只总结剧情,请把下面剧本拆成可用于角色设定、分镜、封面、宣传图和视频镜头规划的生产笔记。
输出结构:
1. 本集一句话看点
2. 场景表:场景编号、地点、时间、在场人物、可见动作
3. 角色记忆:每个核心角色在本集的目标、情绪、关系状态变化
4. 道具线索:首次出现、再次出现、是否有回收或反转意义
5. 关系变化:谁信任谁、谁背叛谁、谁获得权力或信息优势
6. 连续性风险:服装、伤口、道具归属、时间跳跃、出入口方向
7. 视觉下一步:哪些场景适合做分镜、封面、宣传图、镜头参考
8. 推断标记:事实来自剧本,还是你的合理推断
这个提示词的重点是让模型分清“剧本事实”和“模型推断”。对后续图片和视频生成来说,这一点很重要。事实可以进入角色和连续性规则,推断则需要创作者确认。
用 DeepSeek V4 先整理容易违规的提示词
很多短剧创作者卡住,不是因为没有想法,而是提示词一直被判定为风险、表达太夸张,或者生成结果总是偏离剧本。这个时候不要只在原提示词上反复加词。更稳的做法,是先让 Arcloop agent 用 DeepSeek V4 把提示词拆成四层:
| 原问题 | Agent 应该改成什么 | 为什么有用 |
|---|---|---|
| 情绪词太重 | 可见表情、动作、距离和站位 | 模型更容易画出画面,而不是猜语气 |
| 冲突描述太模糊 | 谁在场、谁先动作、谁后反应 | 减少角色关系和镜头顺序跑偏 |
| 审核风险不清楚 | 标出风险词、替代表达和安全边界 | 方便创作者改写,而不是盲试 |
| 画面要求太散 | 场景、角色、道具、光线和构图分开写 | 后续图片和视频生成更稳定 |
可以这样使用:
请把下面短剧画面提示词改成更适合图片/视频生成的制作说明。
要求:
1. 不要绕过审核,不要保留高风险表达。
2. 先指出哪些词可能导致审核或画面跑偏。
3. 把内容改写成可见动作、角色状态、镜头距离、场景道具和情绪节拍。
4. 保留剧情张力,但不要加入剧本里没有的设定。
5. 输出一版安全制作说明和一版更短的生成提示词。
这样写的价值,是把“违规提示词怎么改”“AI 视频提示词怎么写”“短剧分镜提示词怎么稳定”放到同一个流程里处理。DeepSeek V4 负责读懂语义和改写结构,Arcloop agent 负责把它变成后续角色图、分镜图、封面图或视频镜头能用的生产输入。
这仍然需要创作者最终确认。平台规则、模型策略和地区要求都会变化,所以提示词整理应该服务于合规表达和可审核生产,而不是承诺任何内容一定通过。
短剧剧本拆解通常要输出什么
短剧剧本拆解不是只要故事梗概。面向后续 AI 生成,至少要输出这些内容:
| 制作问题 | 对应输出 | 后续去向 |
|---|---|---|
| AI 短剧剧本拆解 | 场景表、角色表、道具线索、关系变化 | 故事记忆和审核依据 |
| 短剧分镜脚本 | 每场可见动作、反转点、镜头顺序 | 分镜网格 |
| 短剧提示词 | 单个图片或视频资产的明确约束 | GPT Image 2 或视频模型 |
| 提示词违规怎么改 | 审核风险、模糊表达、替代表述和可见动作边界 | Arcloop agent 提示词整理 |
| 角色一致性 | 外貌锚点、口吻、服装、关系状态 | 角色连续性手册 |
| 封面和宣传图 | 本集看点、冲突、关键道具、标题安全区 | 封面制作说明 |
DeepSeek V4 更适合先做前两层:读懂剧本并整理结构。提示词和图片生成应该放在创作者确认之后。
DeepSeek V4 输出应该长什么样
一个合格的输出不需要非常复杂,但要稳定。
| 模块 | 示例格式 | 审核方式 |
|---|---|---|
| 本集看点 | “女主在订婚宴上发现戒指属于失踪姐姐。” | 是否能解释本集为什么值得看 |
| 场景表 | “S04,宴会厅,夜,女主/男主/继母在场,戒指被展示。” | 是否按剧本顺序排列 |
| 角色记忆 | “女主从试探变成确认怀疑,开始主动逼问。” | 是否能进入角色连续性手册 |
| 道具线索 | “戒指:S01 提到,S04 出现,S09 成为身份反转证据。” | 是否能用于封面或分镜 |
| 关系变化 | “男主从保护继母转向怀疑继母。” | 是否能影响镜头距离和站位 |
| 连续性风险 | “女主 S04 后仍穿带酒渍礼服,直到 S07 换装。” | 是否能约束图片生成 |
| 视觉下一步 | “S04 适合封面,S09 适合 3x3 分镜反转格。” | 是否能进入 GPT Image 2 制作说明 |
如果输出只有剧情简介,没有这些结构,就还不能进入 AI 短剧生产链路。
和 GPT Image 2 怎么衔接
DeepSeek V4 适合处理“读懂剧本并拆成生产笔记”。GPT Image 2 适合处理“把确认后的视觉制作说明渲染成图片”。两者不要混在一步里。
更清晰的顺序是:
- DeepSeek V4 拆解剧本。
- 创作者确认场景、道具、关系变化和视觉候选。
- 角色连续性手册统一人物外貌、口吻和状态。
- 分镜规划确定九个分镜格或镜头顺序。
- 把单个资产的制作说明交给 GPT Image 2。
- 用剧本拆解结果审核图片是否漂移。
如果下一步是图片生成,可以继续看 GPT Image 2 怎么做短剧角色图、分镜和封面。
适合写进 Arcloop 的产品路径
在 Arcloop 里,这类能力应该被描述为“从剧本生成可复用故事材料”,而不是“一个模型自动完成短剧制作”。
更准确的产品路径是:
- 上传或粘贴短剧剧本。
- 让视频智能体先做 DeepSeek V4 风格的剧本拆解。
- 得到场景表、角色记忆、道具线索、关系变化和连续性提示。
- 从这些笔记里生成角色连续性手册、分镜网格、封面说明、宣传图说明和视频镜头规划。
- 再进入图片或视频生成。
准备测试这个流程时,可以先在 Arcloop Worlds 建立项目世界,把剧本、角色和场景沉淀成可继续扩展的资产。
FAQ
DeepSeek V4 能不能直接拆短剧剧本?
可以测试,但不要只让它总结剧情。更适合的任务是把剧本拆成场景、角色、道具、关系变化、连续性风险和视觉下一步。
DeepSeek V4 和 GPT Image 2 在短剧里怎么分工?
DeepSeek V4 更适合做剧本阅读和生产笔记,GPT Image 2 更适合根据确认后的制作说明生成角色设定图、分镜图、封面和宣传图。
DeepSeek V4 能直接生成短剧分镜提示词吗?
可以生成草稿,但最好先让它输出场景表、角色状态和道具线索,再把其中一场转成分镜提示词。直接从整部剧本生成提示词,容易丢掉人物关系和反转顺序。
DeepSeek V4 是否适合做图片或视频生成?
这篇文章把 DeepSeek V4 放在文本剧本拆解层,而不是图片或视频生成层。短剧生产里更稳的分工是:文本模型负责读剧本、拆结构、标记事实和风险;图像或视频模型负责把确认后的制作说明渲染出来。
为什么要标记“事实”和“推断”?
因为剧本事实可以直接进入连续性规则,模型推断需要创作者确认。混在一起会让后续封面、分镜或视频镜头把不确定内容当成设定。
DeepSeek V4 适合做长剧本还是短提示词?
它更适合被测试在长文本剧本、分集大纲、人物关系和多场景信息整理上。短提示词当然也能处理,但发挥不出剧本拆解层的价值。
Arcloop 会固定使用 DeepSeek V4 吗?
不应该这样承诺。更准确的说法是:Arcloop 会根据效果、成本和稳定性选择文本模型;这篇文章用 DeepSeek V4 解释中文长剧本拆解方法。对创作者来说,关键是 Arcloop 的 agent 文本模型能力可以免费用于剧本拆解、结构重写和连续性检查。
参考资料
准备好实现你的创意了吗?
立即加入 Arcloop,开始生成你自己的故事。
相关文档

生成故事板
Arcloop Storyboard Generator:从剧集到视觉镜头 介绍 Arcloop 中以故事为先的 AI 视频创作流程,帮助你从创作上下文推进到可复用的生产资产。

创建你的剧集
Arcloop 智能镜头规划:如何高效规划镜头 介绍 Arcloop 中以故事为先的 AI 视频创作流程,帮助你从创作上下文推进到可复用的生产资产。

AI 短剧角色连续性手册怎么写
AI 短剧角色手册:如何构建和使用 介绍 Arcloop 中以故事为先的 AI 视频创作流程,帮助你从创作上下文推进到可复用的生产资产。

AI 视频里怎么保持动漫角色一致
如何在 AI 视频生成中保持动漫角色一致 介绍 Arcloop 中以故事为先的 AI 视频创作流程,帮助你从创作上下文推进到可复用的生产资产。